- Software
- Open access
- Published:
Simulation applications to support teaching and research in epidemiological dynamics
BMC Medical Education volume 22, Article number: 632 (2022)
Abstract
Background
An understanding of epidemiological dynamics, once confined to mathematical epidemiologists and applied mathematicians, can be disseminated to a non-mathematical community of health care professionals and applied biologists through simple-to-use simulation applications. We used Numerus Model Builder RAMP Ⓡ (Runtime Alterable Model Platform) technology, to construct deterministic and stochastic versions of compartmental SIR (Susceptible, Infectious, Recovered with immunity) models as simple-to-use, freely available, epidemic simulation application programs.
Results
We take the reader through simulations used to demonstrate the following concepts: 1) disease prevalence curves of unmitigated outbreaks have a single peak and result in epidemics that ‘burn’ through the population to become extinguished when the proportion of the susceptible population drops below a critical level; 2) if immunity in recovered individuals wanes sufficiently fast then the disease persists indefinitely as an endemic state, with possible dampening oscillations following the initial outbreak phase; 3) the steepness and initial peak of the prevalence curve are influenced by the basic reproductive value R0, which must exceed 1 for an epidemic to occur; 4) the probability that a single infectious individual in a closed population (i.e. no migration) gives rise to an epidemic increases with the value of R0>1; 5) behavior that adaptively decreases the contact rate among individuals with increasing prevalence has major effects on the prevalence curve including dramatic flattening of the prevalence curve along with the generation of multiple prevalence peaks; 6) the impacts of treatment are complicated to model because they effect multiple processes including transmission, recovery and mortality; 7) the impacts of vaccination policies, constrained by a fixed number of vaccination regimens and by the rate and timing of delivery, are crucially important to maximizing the ability of vaccination programs to reduce mortality.
Conclusion
Our presentation makes transparent the key assumptions underlying SIR epidemic models. Our RAMP simulators are meant to augment rather than replace classroom material when teaching epidemiological dynamics. They are sufficiently versatile to be used by students to address a range of research questions for term papers and even dissertations.
Introduction
Motivation
The COVID-19 pandemic is a wake up call for us to be more prepared and vigilant regarding future pandemics. We can do this by enhancing our understanding of epidemic dynamics and of the most effective mitigation strategies. Part of this preparedness is providing a more sophisticated quantitative epidemiological training to students entering the healthcare and allied industries.
Many excellent text books are available for teaching epidemiological dynamics [1,2,3,4,5,6]. Some require only a beginners understanding of calculus and others a more sophisticated facility with ordinary differential equations. The most mathematically demanding require that the students have some familiarity with stochastic dynamics. This leaves the mathematically unsophisticated epidemiology student out in the cold. These students can be brought back in and provided with a heuristic understanding of epidemiological dynamics through numerical simulation. Of particular importance in this regard is hands on experience with such simulations. The roadblock here is the programming skills of students involved. The solution is to provide supportive software platforms where relative complex models can be implemented with minimal fuss and coding skills.
In this paper, we provide conceptual and simulation support for an epidemiological dynamics instruction, expecting details on specific disease to be found in other prescribed material. We begin with a review of the basic concepts and assumptions implicit in epidemic SIR (S=susceptible, I=infectious, and R=Recovered disease classes) models. We then present an epidemic simulation platform that we built using Numerus Model Builder’s RAMP™ (Runtime Alterable Model Platform) technology. Numerus RAMPs are directly downloadable from the web. Our SIRS RAMPs—we provide both deterministic and stochastic versions—though designed to help illustrate basic epidemiological concepts, may also be used to carry out simulations useful to healthcare professionals interest in exploring some aspects of pandemic management.
Our SIRS RAMPs also include treatment and vaccination classes, which allows us to discuss various aspects of treatment and vaccination strategies on epidemic dynamics. Although we discuss other extensions to SIR models that are needed to increase the utility of such models in formulating disease management policy we do not include this in the RAMPs described in this paper. We have developed other such RAMPs and web-based models for research purposes that include additional disease classes (e.g., individuals in latent, asymptomatic, symptomatic and recovery-with-some-immunity phases, or dead from the disease; [7] and multiple pathogen variants [8]). Future RAMPs developed for research purposes should include demographic structure (e.g., recruitment, births, non-disease deaths, age classes), spatial structure (e.g., meta populations with some mixing, migration) and, in the context of disease ecology systems, multiple hosts with cross species transmission.
Dynamic systems models in general, and epidemic models in particular, can be deterministic or stochastic, continuous or discrete-time, compartmental systems or individual-based formulations [9,10,11]. The simplest are deterministic (no random process are included) and compartmental (all individuals within the same disease class are identical and cannot be differentiated from one another in terms of when they entered this particular disease class). Most of the concept we are interested in can be demonstrated using this type of model. Deterministic formulations, however, are only suitable for modeling epidemic processes that have already taken hold in populations of tens of thousands to millions. By contrast, stochastic models are needed to computing probabilities of pathogen invasion and the probabilities that an epidemic persists when the number of infectious individuals is a tiny fraction of the population [10]. Thus besides providing a deterministic SIR RAMP as the mainstay of our presentation, we also include a stochastic compartment SIR RAMP to illustrated concepts relating to epidemic emergence and extinction. Stochastic individual-based models are needed if we want to include processes relating to length of time an individual has spent within a particular disease state (=class), or relating to other individual level phenomena. Such considerations, however, are beyond the scope of the material presented here.
Epidemic modeling concepts
Population models are idealizations of reality that include only those processes essential to addressing particular questions at hand [12,13]. They embody several key concepts and explicitly or implicitly include a number of assumptions that render the models a caricature of the real world. The following are a set of basic concepts and assumptions regarding the building of SIR epidemic models. The additional concepts that follow these include ways of making SIR models reflect population structures that may be critical to the utility of the model as a tool for enhancing understanding and identifying effective mitigating strategies for managing epidemics.
Primary concepts
-
Homogeneous population assumption All individuals are assumed to be identical with respect to the disease process (same contact, recovery, disease-induced mortality and immunity-waning rates, as well as the same levels of susceptibility and infectivity).
-
Well-mixed population assumption Any individual is assumed to be equally likely to make contact with any other individual in each time period (i.e., no household, healthcare, or spatial structures exist within the population that would lead to different contact rates among different groups of individuals).
-
Disease class structure We assume that each individual belongs to one of the following three disease classes or, equivalently, be in one of the following three disease states—susceptible (S), infectious (I), and recovered with immunity (R). We may also keep track of the number of individuals that have died from the disease (D) (which can be thought of as a fourth disease state; see Fig. 1), are currently being treated (T), or have in the past been vaccinated (V). Note that sometimes we use X or Y to represent an unnamed disease class: thus in our treatment X or Y may represent, S, I, R, V, T, or D.
Fig. 1 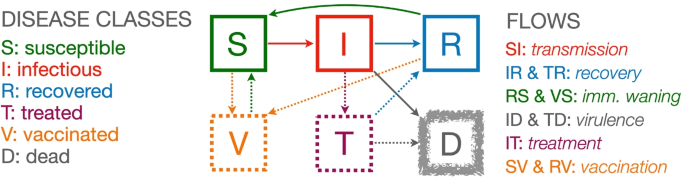
A compartmental flow diagram of an SIRS+TV epidemic process (disease classes S, I and R, the three solid squares) with the addition of deaths (D, fuzzy square) and mitigation classes (V and T, two broken squares)
-
Fundamental unit of time We need to decide on a fundamental unit to monitor the passing of time (t). It is most useful if this unit corresponds to the way epidemiological data are reported, primarily new cases, hospitalizations and deaths per unit time; e.g., daily, weekly, monthly, quarterly or some other unit of time. For fast disease, such as influenza and other respiratory infections, the most useful time unit is typically a day, while for ‘slower’ diseases, such as tuberculosis or HIV, weekly, monthly or quarterly units may be more useful.
-
Variable names versus variable values Our convention is to use roman fonts to name the disease state and italic fonts to represent the variable keeping track of the number of individuals (or density of individuals) in each disease state. Hence X is name of a state and X(t) is the number or density of individuals in this state at time, where X=S, I, R, D, T or V.
-
Flows among disease classes Compartmental models are formulated in terms of flows of individuals from one class to the next. In particular, in many cases the per capita flows per source class are assumed constant over time, though this does not hold for the per capita flow from S to I since this will depend on the proportion of individuals that are susceptible since immune individuals are assumed to be resistant of getting infected (but see waning immunity below). We use the symbol ρXY(t) to represent the per capita flow from disease class X to disease class Y at time t and vice versa when we are making generic statements about flow that are not disease class specific.
-
Lost immunity Individuals in disease class R may return to disease class S because their immunity has waned sufficiently to render them susceptible once again to infection (see Waning immunity below for more details).
-
Rates of change The change in the number of individuals in a particular disease state over a small time interval is given by the rate at which individuals enter this status minus the rate at which they leave this state over this interval of time.
-
Mathematical representation We use t to denote the current time and [t,t+1] to denote the up coming interval of time. In a deterministic model, using \(\frac {dX}{dt}\) to represent the rate of change of the number of individuals in disease class X to all other disease classes, the dynamic equation for this class is given by
$$\begin{array}{@{}rcl@{}} \frac{dX}{dt} & = & \text{(all flows into X at time } {t}) - \text{(all flows out of X at time } {t}) \\ & = & \quad \ \ \sum\limits_{\text{all Y } \ne \text{ X}}\rho_{\text{YX}}(t)Y \quad - \quad \left(\sum\limits_{\text{all Y } \ne \text{X}}\rho_{\text{XY}}(t)\right)X \end{array}$$(1) -
Deterministic versus stochastic models If the large population is relatively large (e.g., millions) and the number of infectious individuals is at least a few hundred, then we model change deterministically in terms of the proportion of individuals that become infected over an interval of time. In smaller populations, or if we are interested in how the epidemic gets started, then we model change stochastically in terms of the probable number of individuals that become infected over an interval of time.
-
How to think about stochasticity in relation to disease class size If with flip a fair coin many times, then as the number of times increase, so the certainty increases that half of the flips will be heads and half will be tails. If the number of flips is very large then we can ignore that fact these numbers will not be exactly 0.5 heads and 0.5 tails, because the approximation gets better as the number of flips increases. Thus when we formulate a deterministic model of an epidemic, we often remark that this model only applies for ‘large class sizes’ which means populations containing at least hundreds of thousands of individuals and hundreds of infectious individuals. In small populations, we have to account for the vagaries of probabilistic events by formulating a stochastic model. The fact that stochastic considerations are always important at the start or end of an epidemic, when the number of infectious individuals is just a few, implies that deterministic epidemic models cannot answer some critical questions about whether or not an epidemic will take off, or exactly when an epidemic may be extinguished. Stochastic models require drawing values from binomial and multinomial distributions, as will be detailed in “SIRS discrete and stochastic formulations” sections and 4.
-
Variable types The notion that the variables X=S, I, R, D, T and V represent integer values is not fully compatible with the formulation of a continuous time deterministic model: in these models disease class variables actually take on continuous rather than integer values. Variables in continuous time models are, thus, more properly thought of as representing the density of individuals across undefined space of unlimited extent, which itself is a modeling idealization. In stochastic models, the values of the variables X are treated as integers.
-
Definition of the reproductive value/number of a disease The reproductive value of each infectious individual in a group of similar individuals is defined to be ‘the expected number of other individuals each of these infectious individuals will go on to infect before these infectious individuals either recover or die.’ This values is highly context dependent and will change dramatically through the course of an epidemic.
-
Definition ofR-zero (R0) At the start of an outbreak of a new disease, when everyone except the first case (aka as ‘patient 0’ or the ‘index case’) is susceptible, the basic reproductive value is referred to as R-zero [14,15]. The disease has the potential to become an epidemic only if R0>1, otherwise the outbreak will fail or just peter out after the first few cases (aka a ‘stuttering transmission chain’ [16]).
-
Definition ofR-effective If, initially R0>1, and an epidemic breaks out, then the average number of new cases that each individual infected at time t causes is called R-effective at time t (Reff(t)), which in the basic SIR model gets smaller with time, as the proportion of susceptible (S) to immune (R) individuals decreases over time. This leads to a steady decrease in Reff(t), from an initial value Reff(t)=R0 to a time where Reff(t)=1. At this point, the incidence begins to decline and Reff(t)<1 continues to fall because as the ratio of susceptible to immune individuals is also declining and not longer able to sustain the epidemic.
-
Cessation of an epidemic An epidemic ceases when prevalence declines to 0, which in a deterministic model can only happen asymptotically as t→∞. In stochastic models this happens in a finite time.
-
Endemicity In populations where waning immunity causes individuals in R to become susceptible once more (i.e., transfer back to S over spending some time in R, as in the SIRS model), if this happens at a sufficiently rapid rate, then prevalence will not fall to 0 and Reff(t) will not necessarily decline monotonically once below 1. Rather, Reff(t) will either not fall below 1 or bounce back to approach 1 after falling below 1 and prevalence will stabilize at a level corresponding to a point where Reff(t)=1. If this happens, the disease is said to be endemic and the approach to endemicity may exhibit dampened oscillations in prevalence levels.
-
Per capita contact rate The SIRS model implicitly assumes that transmission can only occur through direct contact of individuals, though individuals do not necessarily need to have physical contact (e.g., short distance airborne transmission enhanced through sneezing, coughing, speaking). In the simplest SIRS models, the per capita rate κ(t) at which individuals contact others is assumed to be constant—i.e., κ(t)=κ0 for all t.
-
Contacts involving pathogen transmission Transmission only occurs when a susceptible and infectious individual contact one another. The per capita rate at which any individual in the population contacts an individual in the infectious class, is the contact rate κ(t) multiplied by the proportion I/N of infectious individuals in the population—i.e., κ(t)I/N. Thus the total rate of contact is the number of susceptible individuals S multiplied by the per capita rate, which thus is κ(t)(SI/N). Only a proportion of these contacts will lead to actual transmission, as discussed next.
-
Risk of transmission Transmission is best thought of as the probability of a sufficiently high dose of pathogens being transferred from infectious individual to a susceptible individual during an event that is characterized as a contact to cause disease in the susceptible individual. Although transmission is highly complicated, depending on how close individuals are and for how long they make contact during a ‘contact event,’ these complexities are washed out through an averaging processes encapsulated in a ‘risk or force of infection’ parameter most often referred to as beta (represented by the Greek letter β). In an SIRS model the actual per capita rate of transmission is thus a concatenation of processes involving contact rates and probabilities of transmission per contact with an infectious individual (this computation is characterized more precisely in “SIRS discrete and stochastic formulations” section). Thus the transmission rate itself is represented by the product βκ(t)I(t)/N(t). In most SIRS models, contact rates are often folded into the value of β, thereby leading the disappearance of the parameter κ.
-
Frequency dependent transmission The per capita contact rate is a constant (i.e., independent of population size) κ(t)=κ0, implying the per capita contact rate of any susceptible with an infectious individual is κ0I(t)/N(t), so the total transmission rate at time t is
$$\text{Total frequency-dependent transmission} = \frac{\beta \kappa_{0} S(t)I(t)}{N(t)}$$(2) -
Mass action transmission If the per capita contact rate scales with population density N, as would be the case if individuals moved around at random making contact as they bump into one another in what is referred to as a ‘mass action process’, then we need to replace κ0 in Eq. 2 by κ0N to obtain
$$\text{Mass action transmission} = \frac{\beta \kappa_{0} N(t) S(t)I(t)}{N(t)}=\beta \kappa_{0} S(t)I(t)$$(3)This type of transmission process only applies to entities that have no autonomy over their movement as the move and bounce around when contacting one another.
-
Adaptive (behavior modified) contact In more sophisticated SIRS models, a behavioral response can be included by assuming that κ(t) depends, say, on the current prevalence I(t)/N(t). We refer to this as an adaptive contact rate because the rate adapts to the level of disease prevalence in the population so as to reduce transmission. In this case we replace the constant basic rate, with an expression that decreases in value with increasing levels of the prevalence I/N (see “Constant and adaptive contact rates” section for a formulation of one such function).
-
Waiting times and relationship to transition rates In SIRS models, if ρX Y is the rate at which individuals in disease class X flow (aka transition) to disease class Y, then it can be shown (Table 1) that the expected time spent in disease class X (aka waiting or residence time in disease class X) when the only path out of X is to disease class Y, is given in our notation (See Table 2) by \(\bar T^{\mathrm {X}}=\frac {1}{\rho _{\text {XY}}}\). Naturally, waiting times are reduced when more then one process exists for exiting disease class X, as discussed in Table 2.
-
Infectious period The infectious period is the waiting time in infectious class I.
-
Latent period In some disease models a latent period is included in which it is assumed that an individual has been exposed to a pathogen and enters a class denoted by E = exposed or, in our formulations by L = latent, before entering infectious class I once the latent period is over. (Such extended models are often referred to as SEIR models). The latent period is the waiting time in latent class L (or E in SEIR models). The addition of a latent period does nothing to alter the epidemic dynamics (e.g., does not influence Reff) other than to introduce a time-delay into the rate at which the epidemic breaks out.
-
Disease-induced mortality (virulence) In some SIRS models, individuals in infectious class I can either recover or die (i.e., the flow out of I is into both R and D, as indicated in Fig. 1)

Students may be introduced to some of these additional concepts, as appropriate to the material presented in instructional settings, although these concepts are not implemented in the deterministic (continuous time) or stochastic (discrete time) SIRS+DTV RAMPs considered here. Other current [8] and possible future SIRS-RAMPs will include some of these concepts.
Additional concepts
-
Disease classes beyond SIR Additional intrinsic disease classes (i.e., other than those associated with interventions) include, as already mentioned, infected but not yet infectious (L = latent, aka E = exposed), as well as infectious without symptoms (A = asymptomatic), or contacted (C) but not necessarily on the way to becoming infectious (i.e., individuals in C may either go back to S or onto L) [7]. Class A is extremely important in masking the seriousness of an outbreak, as we have seen with the recent COVID-19 pandemic [17,18]. Class C allows for considerations of the contact tracing and subsequent quarantining of individuals who may or may not then go onto to become infectious [19,20].
-
Waning immunity Individuals are assumed to be immune for a time after recovering from infection (i.e., once no longer infectious). This immunity wanes over time with individuals becoming increasingly susceptible over time. In SIRS models, however, the implicit assumption is that individuals in disease class R transfer back to disease class S at a constant rate, irrespective of how long any particular individual has spend in disease class R. In SIRS compartment models, the average time spent by any individual in disease class R, however, is the so-called disease class R waiting time. In reality, it may take a higher dose of pathogen to infect individuals a second time.
-
Breakthrough infections These are defined to be infections in individuals that have been vaccinated [21], but this notion could equally well apply to individuals that have been previously infected. In compartmental models, flows from R and V back to S allow us to account for breakthrough infections at a very crude level because they do not take the subtleties of waning immunity into account for individuals in R or V. A refined treatment requires an individual-based or agent-based approach as described below (also see [8] for including of breakthrough infections in a multi-variant pathogen setting).
-
Demographic class structure Transmission and mortality rates may often be age dependent. For example, the global influenza pandemic of 1917-1919 proved to be most virulent for young adults while the COVID-19 pandemic was most lethal for the elderly. When age-structure is added to a model then a ‘mixing matrix’ is needed to describe the relative frequencies with which individuals of different ages make contact with one another [22]. Other demographic classes may be job related, such as partition off healthcare workers [23] or teachers for special consideration.
-
Metapopulation structure The spatial homogeneity assumption implicit in SIRS models can be obviated by dividing a population into a number of sub-populations, each of which is itself homogeneous, but a mixing/movement matrix is needed to describe how individuals in one sub-population contact or join individuals in another sub-population [24,25,26,27].
-
Epidemic versus demographic time scales The basic SIRS model does not include rates at which new individuals join a population (aka recruitment), are born into a population or die from natural causes. If an epidemic occurs on a time table that is fast compared with the demographic processes of births, maturation of individuals (as in recruitment to a sexually active population in the context of sexually transmitted diseases) or deaths, then these demographic processes can be ignored [28]. In the case of ‘fast disease’ such as influenza in humans, the epidemic may often burn through the population in months, while births and deaths only lead to significant changes population numbers on the scale of decades. For slower diseases such HIV-AIDS, tuberculosis, or leprosy, the epidemic process may be in the same time scale as the demographic time scales as births an natural deaths, particular in species that have generation times measure in years rather than decades. Beyond epidemic and demographic time scales, longer evolutionary time scales may also be considered [29].
-
Multiple hosts In zoonotic diseases transmitted from animal to human hosts, such as certain strains of influenza and cold viruses, it may be important to consider how the pathogen is transmitted back and forth between human and animal populations [30,31]. This is certainly the case for avian influenza [32].
-
Multiple pathogen variants During the course of an epidemic the pathogen may evolve, as occurred in the recent COVID-19 pandemic. In this case, particularly if some variants are much more transmissible or lethal than others, models that incorporate multiple pathogen strains may be used to help manage strain proliferation [8].
-
Other modes of transmission SIRS models are applicable to directly transmitted diseases and are generally not applicable to pathogens that are transmitted by a vector (e.g. tick or mosquito borne diseases) when the pathogen in the vector population varies over time. In this case, the pathogen levels in both populations need to be modeled, as well as the rates of contacts between hosts and vectors and how these contacts may vary over time [30,33]. Beyond vector transmission there are various environmental modes of transmission including water borne [34] and soil borne diseases [35].
-
Agent-based models ABMs, also known in some contexts as IBMs (individual-based models) allow us to focus on the history of individuals [11,36]. Among other things, this means we can directly account for the time that each individual entered a particular disease state and make the exit from that state dependent on how long the individual has been in that state. This individual level control obviates the exponential distribution of waiting times in diseases implicit in compartmental systems models (Table 1), although a somewhat cumbersome ‘boxcar’ extension to compartmental system models allows us to obtain waiting-time distributions that have a humped-shaped distribution with the mode close to the mean (see Appendix B, Supplementary online file or SOF). Such hump-shaped distributions also arise in ABMs if the rate individuals leave a particular disease class increase with the time they have spent that class (see Appendix C, SOF).
Implementation
SIRS epidemic model formulation
Basic model
The continuous time, extended Kermack and McKendrik SIRS (S=susceptibles, I=infected & infectious, R=recovered) epidemic model [5,37] is foundational to the development of epidemiological systems modeling and theory [38]. It is most often formulated in terms of the variables S, I, and R (note we use the roman font mnemonics S, I, and R to refer to the names of the disease classes/compartments and italic fonts to the variables themselves). For the sake of completeness we include a disease class D to account for the dead, but define the number of individuals alive at time t to be
In the context of differential equation models these variables, strictly speaking, should be interpreted as population density variables; though loosely speaking we think of them in terms of numbers in a closed (no births or natural deaths, no migration), homogeneous population (everyone is equally susceptible, infectious, and likely to make contact with any other individual). From the general systems description given by Eq. 1, if the flow of individuals from disease classes/compartments S to I, I to R and R back to S, plus a flow of individuals from I to D (disease-induced mortality process) are respectively represented by the per capita flow rates ρSI, ρIR, ρRS, and ρID, (solid arrows in Fig. 1), then we obtain the deterministic continuous-time epidemic compartmental SIRS model
We note the initial conditions included here reflect the start of an epidemic caused by a novel pathogen (and variables, though actually continuous, are interpreted in terms of numbers of individuals). Other initial conditions can be assumed when using Eq. 5 to simulate a population that is already part way into an epidemic.
In practice, once the values or functional forms of the flows ρXY have been specified for X, Y = S, I and R, solutions will be generated over the time interval [0,tfnl] using numerical simulation techniques.
Constant flow rates
In the simplest case, apart from the per capita susceptible flow rate ρSI, the flows are assumed to be constant and the transfer of individuals from one disease state to another follows an exponential process. The consequences of this assumption are discussed in Table 1.
Extra information. The assumption of a constant flow through X, resulting in an exponential exit rate for all members currently in X, is unrealistic. To see this, consider any particular individual entering X at time t=0. The probability this individual leaves X during the interval [t,t+1] is given by (recall Eq. 1.1 in Table 1)
This probability has a maximum value of 1−eρ at t=0. If individuals spend several units of time in X, it is much more reasonable to assume that the probability they leave X in any particular unit of time is around the mean time \(\bar T^{\mathrm {X}}=\frac {1}{\rho }\) spent in X rather than the very first period of time. One can achieve this more reasonable departure behavior in a continuous-time differential equation model by dividing the disease class X into a say K>1 sub-compartments and have an individual pass through each of these sub-compartments at a rate Kρ, resulting in so-called box car models (Appendix B, SOF). The exit process from a box-car model with K compartments is by an Erlang distribution with shape parameter K and scale parameter Kρ rather than and Exponential distribution with scale parameter ρ. In an Erlang distribution for which K>1, an individual is most likely to leave during the period that surrounds the mean time that it spends in X, which is still \(\bar T^{\mathrm {X}}=\frac {1}{\rho }\), rather than immediately on entering, as implied by Eq. 6 for the exponential case. The box car or Erlang model is described in more detail in Appendix B (SOF).
Disease transmission
The per capita flow rate ρSI from the susceptible to the infectious class is more complicated than the per capita flow rates between the other disease classes. This flow rate represents a disease transmission process that depends on susceptible and infectious individuals making contact with one another. This contact process in the original Kermack-McKendrick model was assumed to be dependent on the product S(t)I(t) of the susceptible and infectious classes. This approach draws its inspiration from the Law of Mass Action that pertains to chemical kinetics. The resulting incidence—the rate of new infections—then takes on the eponymous βSI transmission rate, where β is a parameter whose value reflects the joint effects of both an underlying contact rate and a ‘probability of transmission’ per contact (inverted commas are used because only in the stochastic model, as developed in “SIRS discrete and stochastic formulations” section, are probabilities made explicit; also see “The basic reproductive rate r-zero and probability of infection” section on how to derive the probability of transmission per contact). A more appropriate approach to modeling disease transmissions, and hence the incidence rate, in humans (at all but the very lowest population densities found in rural areas) is to assume that: 1.) each individual in the population contacts others at a per capita rate κ; and 2.) only the proportion of contacts with infectious individuals—i.e., I(t)/N(t)—can lead to transmission. Further, not every contact will lead to transmission, but will be scaled according to a force of infection parameter β. In this case, we typically represent transmission by a per capita susceptible function that has the frequency dependent form [39]
In this case, total incidence, which we denote by Δ+I(t) (Δ+, is used to denote change due to new additions to I, before accounting for the individuals that leave I), is now given the function
More elaborate incidence functions have been proposed [40], particularly in the disease ecology literature [41]. Equation 7, however, is the one we will focus on throughout this exposition. Also, in most of the literature, the processes of contact, represented by the parameter κ and force of transmission per contact, represented by the parameter β, are not separated but are effectively rolled into a single constant βκ=κ×β, with no subscript used (equivalent to setting κ=1). In this case, the contact process itself is no longer transparent. We believe that the contact process should always be explicit as a reminder that transmission requires ‘effective contacts’ to be made. Note that it does not make SIR models dynamically more complex when βκ is represented as the product of two constants: i.e., when βκ=κ×β. An effective contact is one that result in pathogen transmission. Contacts that do not result in transmission are part of more complex epidemic models that consider quarantining as a mitigation strategy [7] because not all quarantined individuals become infected.
Constant and adaptive contact rates
Most SIR models implicitly assume a constant contact rate
Arguably, one of the most important modifications to the transmission rate and incidence expressions given by Eqs. 7 and 8 is to account for changes in contact rates once a pandemic has started. This behavior was seen with regards to the Ebola pandemic of 2015 [36], as well as COVID-19 pandemic [7]. One way to deal with this is to assume the contact rate adapts, by decreasing either as a function of incidence (Eq. 8) or the proportion of individuals that are infectious (i.e., I(t)/N(t)). If we assume the latter, then a three parameter form for the contact rate κ(t), that depends on a basic contact rate κ0>0, an infectious proportion switching point Pκ∈(0,1), and an abruptness switching parameter σκ≥0 is given by the function [8]:
The switching point parameter σκ may be set to 2 for gradual switching, 5 for relatively abrupt switching, or 20 to approximate a step function around the infectious proportion switching point Pκ.
The basic reproductive rate r-zero and probability of infection
The basic reproductive rate, R0, of a disease at the start of an epidemic in a population that has never been exposed to the pathogen causing the outbreak represents the number of expected new cases that the index case (aka patient zero) will cause. This number is represented by
The product κβ can be used to obtain the incidence per susceptible over a short time interval Δt at the start of the epidemic (also interpreted as the probability of a susceptible becoming infected over [0,1]) by solving for the incidence over the period t∈[0,Δt], assuming I0=1. This number can be obtained by first solving the differential equation
Integrating the above equation for the condition I0=1 (to see how many susceptibles are infected by a single inectious individual; and assuming both κ and β constant over this interval) implies that S(Δt)=e−κβΔtS0. Since the expected proportion of susceptibles that will become infected over [0,Δt] (i.e., those that leave class S for class I) is given by \(p_{\text {inf}}=\frac {S(0)-S(\Delta t)}{S(0)}\) (also interpreted as the initial probability of infection), we obtain the expression
Finally, we reiterate that most SIRS formulations do not explicitly identify a contact rate κ so that this parameter does not appear at all in these formulations and also that γ is used instead of ρIR (γ≡ρIR). In such cases, R0=β/γ and pinfect(0,Δt)=(1−e−βΔt). But, as previously mentioned, it is useful to explicitly include κ because it is needed to discuss adaptive contact and provide the structure needed to introduce quarantine rates in a sensible way.
SIRS discrete and stochastic formulations
The discretized version of the SIRS model when disease-induced deaths are not considered is given by the following set of t=0,1,...,tfnl when simulated over the interval [0,tfnl]
where the proportions pXY are related to the rates ρXY by the equation (see Table 1 and cf. Eq. 12)
Thus, as required, pXY=0 when ρXY=0 and pXY→1 as ρXY→∞.
A discrete-time stochastic version of this model is obtained from Eq. 13 by assuming that the quantities pSI represent probabilities proportions. (Note: Continuous-time stochastic models require a level of mathematical treatment beyond the scope of this presentation; e.g, see [42]). In this case, the simulation takes the form of a discrete-time Monte Carlo process in which drawings from a binomial distribution are considered rather than computations of proportional change. Specifically, simulation involves the following drawings, using the following notation to denote such drawings (aka samplings):
We note that \(\hat X_{p}\) is the actual number of actual objects drawn or sampled from a total of X objects, where each object has the probability p of being selected (and hence 1−p of not being selected).
Formally, our stochastic model is the following Monte Carlo simulation that begins with specified values for S(0), I(0), R(0) and D(0) and continues with successive samplings for t=1,2,...,tfnl:
SIRS+D stochastic formulation
The discrete-time and stochastic models given by Eqs. 13 and 15 do not include disease-induced mortality (aka to mathematical epidemiologists as virulence). Thus they are only useful for considering the start or initial growth of epidemics or epidemics where disease-induced mortality is inconsequential. Including deaths requires consideration of competing rates/risk for individuals leaving particular disease classes. For example, when deaths are considered individuals leave class I to either recover (R) or die (D). In this case, a competing rates formulation (Table 2) is needed to simulate outcomes. In particular, in the SIRS+D continuous-time model (Eq. 5) the prevalence equation (I(t)) involves the competing rates of recovery (ρIR) and disease-induced mortality (ρID). Thus applying a competing rates formula, we obtain (Table 2, Eq. 2.3 with Δt=1)
Since individuals in the prevalence class I are now faced with two possibilities of where to go—i.e., recover or die—the stochastic version of the model requires that the binomial drawing be replaced with a multinomomial drawing that depends on the two probabilities pIR and pID. This requires that we use a multinomial function that, in general, for the case of n−1 leaving options with competing probabilities pi, i=1,...,n−1, and not to move at all with probability \(p_{n}=\left (1-\sum _{i=1}^{n-1}p_{i}\right) \ge 0\). We use the following convention to specify the values obtained in one such multinomial sampling:
Thus the model is now given by (cf. Eq 15)
SIRS+DTV: including treatment and vaccination
We now add treatment (T), and vaccination (V) classes to our SIRS+D model and define
For simplicity, we assume that individuals under treatment are no longer able to transmit pathogens to the population at large—i.e., they are essentially completely quarantined. In reality, however, the situation is much more complicated than this: the ability of individuals under treatment to transmit pathogens depends on how strict the quarantine procedures are. In addition, if we structure the population to include healthcare workers or members of the infected individuals household, then clearly these healthcare workers and household members are likely to be at some particular risk of infection from individuals under treatment. Thus, moving beyond our simplifying assumption of individuals under treatment being effectively completely quarantined requires additional model structure and transmission parameters, which is not included in the model formulated here.
Deterministic formulation
The dynamic equations consist of the following system of 5 differential equations, augmented by the three integrations that allow us to keep track of the accumulating deaths (D(t)), cases that are treated (Ttotal(t)), and individuals that are fully vaccinated (Vtotal(t))
For simplicity, we will initially assume a constant treatment rate ρIT=ρtreat that is implemented from the onset of the epidemic being modeled. However, we will place a maximum Tmax on the number of individuals that can be in treatment at anyone time, due to a limited capacity of the healthcare system to take care of sick individuals. Thus, we have
This intervention, however, will be available to the user to elaborate through a RAM (runtime alternative module) that is the hallmark of our RAMP (runtime alterable model platform) technology. Equation 21 will be the Default formulation while alternative 1 will be constant application of ρIT with not upper limit.
For the sake of completeness, we note that since the outflow from I now includes both flows to R, T, and D the expression for R0 in Eq. 11, while individuals in T and D are assumed not to transmit pathogen (note for disease, such as Ebola, pathogen is transmitted from individuals in D preparation of the corpses for burial [43]) now becomes
For simplicity, we will initially assume a constant vaccination rate v that is implemented from time \(\phantom {\dot {i}\!}t_{\mathrm {V}_{\text {on}}}\) onwards. As with treatment, we will place an upper bound on the number of vaccination regimens that can be administered, where a vaccination regimen is defined to be a complete course that consists of one or more shots over a specified interval of time. Note, for simplicity, we assume that the full effect of the vaccination starts at the time of administering the first shot in the prescribed regimen (at which time the individual is transferred to V from S, C, L, R, or Q, as the case may be). An individual that later transfers from R back to S may then receive a second regime in an ongoing vaccination rollout program. The vaccination rate v itself will be available to the user to elaborate through our Vacc RAM (runtime alternative module). Thus our default vaccination rollout program is defined by
This function will be alternative 1 of the Vacc RAM of our RAMP.
Stochastic formulation
For each time step in the stochastic simulation (t=0,1,2,...,tfnl−1), we need to transform all the rates ρXY(t) (used in the continuous-time formulation) to probabilities pXY(t) using the rates to proportions transformation Eq. 2.2 in Table 2. We then proceed at each time step to use these probabilities in the Monte Carlo drawings followed by computing next values using the updating equations, as specified below:
Once the simulation is complete, we will have generated time series for all the disease class variables X(t), t=0,...,tfnl, X=S, I, R, T and V, as well as an incidence time-series \(\hat S_{I}(t)\) and new deaths time-series \(\Delta D(t)=\hat I_{\mathrm {D}}(t) + \hat T_{\mathrm {D}}(t)\) over t=1,...,tfnl.
RAMP implementation
Here we provide a brief description of the structure and operation of our four RAMPs, each of which is an HTML file the implements the reference models as a Numerus Model Builder RAMP application
-
SIRS_Det.xml implements the continuous-time deterministic model represented by Eq. 5, with ρID fixed at 0
-
SIRS_Sto.xml implements the discrete-time stochastic model represented by Eq. 15
-
SIRS+DTV_Det.xml implements the continuous-time deterministic model represented by Eq. 20
-
SIRS+DTV_Sto.xml implements the discrete-time stochastic model represented by Eq. 24
SIRS+DTV continuous-time deterministic and discrete-time stochastic RAMPs, while the structure and operations of our simpler SIRS continuous-time deterministic and discrete-time stochastic RAMPs are just a subset of descriptions of the more complicated RAMPs once elements relating to death (D), treatment (T) and vaccination (V) processes are removed. The RAMPs are built with the Numerus Model Builder Designer (NMB Designer). Once built the NMB Designer is used to generate a RAMP as an HTML file with a user provided name. This file can then be read and implemented by using NMB Studio. This application is available for free at the Numerus Website (URL). The reader and the RAMP HTML files for the continuous-time deterministic and discrete-time stochastic SIRS+DTV RAMPs are available at our Numerus Model Builder Website, where more information on using these RAMPs is available at the Numerus Website.
Deterministic RAMP dashboard
Once NMB Studio has been download from the Numerus Model Builder Website, installed, launched, and the Continuous-time deterministic SIRS+DTV RAMP HTML file has been read in, the dashboard depicted in Fig. 2 appears. It is used to load saved or reset parameter values for simulations, initiate runs, generate graphs, and save simulation results in the form of CSV files. We note that every object on the dashboard (parameter sliders, RAM rollers, and graphs) has a string of three alphanumeric characters (which we refer to as airport codes) associated with it that is used in scripts to control parameter values, select runtime alternative module (RAM) options, and select among graphing options. The various dashboard windows and their functions are:

The dashboard of the SIRS+DTV continuous time RAMP is depicted here with graphical results of a run made over the interval [0,70] using the set of values appearing in the windows of the 13 sliders available for manipulating 13 parameters (also see Table 1) in the model. Note that in the Epidemic Curves (EPC) graph, the Dead_(D/N) button is in gray because this graph is switched off, though the total number of deaths are plotted (blue curve) in the Accumulated Totals (ACT) graph. Note that the left control roller for Kappa (KAP) is in green because the Constant mode (roller value 1) for this RAM has been selected rather than the Default (which would be in blue and the roller value would be 0), which is the Adaptive Contact mode expressed in Eq. 10 (also see Fig. 4)
-
Top ribbon (from left to right)
-
Run length window Type in the length of the run and then press ‘enter’ on your keyboard
-
S access window button (S On) This window provides the user for a place to load a script written in Ramp Programming Language (RPL) or to write a de Novo script to control and make the current run (see Fig. 4).
-
RAM access button (Op On) This will open the window that allows the user to access the different runtime alternative modules (RAMs) where options are available to use alternative functional descriptions or enter a ’user-defined description’ of a key process in the model.
-
JavaScript window button (Op On) The user can open a window and either load in a script or write a JavaScript to control a run using the Airport codes to access variables and functions (See Fig. 7)
-
dt window This window only appears in the continuous time (and not in the stochastic) RAMP. It is size of the numerical integration interval used to solve the underlying system equations using a Runge-Kutta 4 algorithm.
-
Reset button Use to clear graphs and data from previous run.
-
Single step button Each time this button is pressed the simulation will progress by one time step.
-
Run button After pressing reset to clear previous run data, press this button to initiate a new run.
-
Run progress window In this window, the progress of the computation is monitored by counting down in time from the length of simulation to 0 (i.e., end of simulation).
-
Main window (from left to right and top to bottom)
-
Parameter slidersName (Airport Code, mathematical symbol)
-
Baseline contact rate (KP0,κ0) This parameter in Eq. 10 is the contact rate at the start of the epidemic (i.e., κ(0)=κ0).
-
Contact rate scaling (KPS,Pκ) This parameter in Eq. 10 is the prevalence (proportion of infectious individuals) at which the baseline contact rate is reduced by a half (i.e., κ(t)=κ0/2 when I(t)/N(t)=Pκ).
-
Transmission parameter (BET,β) This parameter, interpreted as the ‘force of infection’ appears in Eqs. 7 and 8, as seen in Eq. 12, when multiplied by the contact rate κ(t) essentially determines the probability of infection per contact.
-
Recovery rate (RIR,ρIR) This is the flow rate from the infectious to the immune disease class: it also is the inverse the infectious period (see Eq. 1.2 in Table 1).
-
Loss-of-immunity rate (RRS,ρIR≡ρIV) These are the rates at which individuals return from disease classes R and V (for simplicity assumed equal in our model) to become susceptible again in disease class S. Their inverse is the period immunity remains effective (see Eq. 1.2 in Table 1).
-
Disease induced death rate (RID,ρID) This parameter, referred to as the virulence parameter α by mathematical ecologists specifies the per capita prevalence rate at which infected individuals die over time.
-
Treat (TRT,ρtreat) This parameter is the rate at which infectious individuals are placed under treatment, provided the treatment capacity Tmax has not been exceeded (see Eq. 21 for details of how ρIT is defined in terms of ρtreat and Tmax). A key effect of treatment is to reduce the rate of contact of infectious individuals in class T compared with those in class I. In our model, we assume that individuals in class T no longer transmit pathogens to susceptible individuals, although in more complex models some transmission may occur, particularly to healthcare workers (but this is assumed to be negligible in our formulation).
-
Treatment capacity (TRC,Tmax) This parameter places a limit on how many individuals can be under treatment at any one time. When this level is reached, then new patients are limited by the rate at which individuals leave treatment because of death or recovery.
-
Treatment discharge rate (RTR,ρTR) This is the rate at which individuals under treatment are released to join the immune class R.
-
Death rate under treatment (RTD,ρTD) This is the rate at which individuals under treatment die from the disease. This rate may be greater or less than the disease-induced death rate for individuals in disease class I—the former when only the most severe cases are treated, and the latter when treatment is at least somewhat effective.
-
Vaccination onset time (VOT,\(\phantom {\dot {i}\!}t_{\mathrm {V}_{\text {on}}}\)) This is the time that the vaccination rollout program begins on the interval [0,tfnl] (i.e., it may be the start of the simulation or some way into the simulation).
-
Vaccination regimens available (VAM,Vmax) This parameter sets an upper limit to the total number of vaccination regimens that can be administered (whether a regimen consists of one, two or more shots in a defined space of time, the number of regimens rather than shots are counted)
-
Vaccination rate (VAR,v) This rate only applies for \(\phantom {\dot {i}\!}t\ge t_{\mathrm {V}_{\text {on}}}\) and as long as Vmax has not been reached.
-
-
RAMsCode name, Descriptive name (Airport code, mathematical symbol) in blue when default option is selected (roller value 0) and in green when an alternative value is selected (roller value 1 corresponds to constant values over the simulation interval, roller values > 1 will be user supplied options; text in red if the reset button needs to be toggled)
-
Kappa, Adaptive Contact (KAP,κ(t)) The Default (roller 0) for this expression, as given by Eq. 10, involves the baseline contact rate κ0, the contact rate scaling constant Pκ and the transmission parameter β. Alternate roller 1, labeled Constant, is the constant value κ0.
-
Treat_Rate, Treatment Flow Rate (RIT,ρIT) The Default (roller 0) for this expression, as given by Eq. 21, involves the baseline treatment rate ρtreat and the treatment capacity parameter Tmax. Alternate roller 1, labeled Constant, is the constant value ρtreat.
-
rSV, Vaccinate S (RSV,ρSV) The Default (roller 0) for this expression, as given by Eq. 23, involves the baseline treatment rate v, treatment onset time \(\phantom {\dot {i}\!}t_{\mathrm {V}_{\text {on}}}\) and the treatment regimens available parameter Vmax. Alternate roller 1, labeled Constant, is the constant value v.
-
rRV, Vaccinate R (RRV,ρRV) The Default (roller 0) and alternative Constant (roller 0) as exactly the same as Vaccinate S. This option has been provided in case the user wants to vaccinate disease class R in a different manner to disease class S. This would require the classes R and S can be distinguished by the healthcare establishement.
-
-
GraphsName (Airport code)
-
Epidemic curves (EPC) This graph allows the user to plot the proportion of individuals in disease classes S, I, R, and D over the chosen simulation interval or to select one of these four variables to create a comparative graph over multiple runs.
-
Accumulated totals (ACT) This graph allows the user to plot the accumulating number of deaths (D(t)), vaccinated (Vtotal(t)) and treated (Ttotal(t)) individuals as time progress, or to select one of these three variables to create a comparative graph over multiple runs.
-
Epidemic progress (EPP) This graph allows the user to plot the effective reproductive rate (Reff(t)) or prevalence (I(t), repeat of second graph in EPC) over time, or to select one of these two variables to create a comparative graph over multiple runs.
-
Stochastic SIRS+DTV RAMP dashboard
As with the Continuous-time SIRS+DTV RAMP, the latest available version of the Stochastic SIRS+DTV RAMP can be downloaded at our Numerus Model Builder Website where more information on using the RAMP is available. The dashboard of the Stochastic SIRS+DTV RAMP is the same as its continuous time counterpart, except the dt window is now replaced as follows:
-
Seed window This window (center of top ribbon) anchors the sequence of pseudo random numbers used to in the simulation to a particular starting point: if this window is empty, then the starting point is random, otherwise it can be specified by a number ranging for 0 to 264−1.
There are also one additional slider in the stochastic dashboard
-
Parameter slidersName (Airport Code, mathematical symbol)
-
Popsize (PSZ,N0) This parameter is the initial population size N0 that appears in Eq. 24, where the initial number in disease class S is S(0)=N0−1.
-
The reason why population size does not appear in the Continuous-time SIRS+DTV RAMP is that the solution to continuous time model Eq. 20 is scale free relative to the size of N0 (i.e. every equation in this model can be divided by N0 to obtain a system of equations on the time course of the proportions S/N0, I/N0, R/N0, T/N0, and V/N0, so that the equations are now independent of our choice of N0, provided the initial conditions are set to the corresponding set of fractional values. On the other hand, the variance associated with demographic stochasticity depends on absolute values (viz., the variance associate with multinomial sampling is inversely proportional to the square root of population size), which implies that the behavior of the initial outbreak is nearly (i.e., provided S(t)/N(t) remains very close to 1) independent of population size provided the transmission is purely frequency dependent (i.e, does not have a density dependent component to it).
Every run of the stochastic RAMP for a given set of parameter values will be slightly different, unless these runs are made with the same value inserted in the Seed slot in the middle of the top ribbon of the stochastic SIRS RAMP (Fig. 3). To make sure that the same seed is used at the start of a new run, the Restart RNG on Reset square below the seed window can be checked. To answer many questions, it is often likely to be more useful to make multiple runs and provide statistics related to quantities of interest, than to make and present a single run. This idea will be further developed in the “Stochastic SIRS dynamics” section. In terms of visual interest, repeated runs can be compared by selecting the Comparison mode slot above each graph, and making sure that all by one of the graphs that can be plotted with each graph (see lists below each graph in Fig. 2, which can be selected or deselected by clicking on the appropriate small circular button. In the two graphs in Fig. 3A. the proportion of immune individuals and number of infectious individuals are plotted for 10 comparative runs for set of values indicated in the slider windows and in Table 3 when not available for slider selection.

Ten comparative runs of the stochastic SIRS RAMP using the parameters values depicted by the sliders (or fixed according to values listed in Table 1). In panel A. the population size is 1000, in panel B. it is 10,000, while in panel C. a vertically magnified version of prevalences for the three runs that failed to take off in panel A (Runs 6, 7 and 9; such runs are expected, as discussed in the Results Section in the context of Eq. 25) are plotted on their own
Operation of runtime alternative modules (RAMs)
The four RAMs all operate in the same manner. The Default modes (value 0 on roller selectors and text in blue) for the Adaptive Contact, Treatment Flow Rate, Vaccinate S and Vaccinate R modules are respectively coded by Eqs. 10, 21, 23 and, again, 23. Along with these a Constant alternative mode (value 1 on the roller selectors and text in green, though text is in red when still to be included by pressing the reset button on the top ribbon of the Dashboard) is available for each of these. Information on these alternatives is provided in the window opened by toggling the Op On button, second from the left on top ribbon of the dashboard (Fig. 2). This window (Fig. 4A.) allows the user to select the RAM of interest (bottom left hand list). Once selected (in Fig. 4A., for say the Adaptive Contact RAM, the Default Kappa option is shown) the window provides an option to select the Default RAM (left text inner window contains general information; the right top text inner window contains specific information pertaining to the particular alternative selected; and the bottom right inner window contains the coded expression that will be used). Panel B, Fig. 4B.) depicts selection of alternative 1 for the Kappa RAM along with the its specific information inner window and coding inner window. Next to the buttons to select the alternatives 0 and 1 is a “+” button (bottom of panel B, Fig. 4) that users can be use to add as many alternatives numbered 2, 3,... etc., as desired.

When the Op On button (second button from the left on the top strip of an SIRS+DTV RAMP, as depicted in Fig. 2, is selected the window depicted here opens (panel A.). At the bottom left hand side we see that we have four RAMs (runtime alterable modules) options pertaining to the formulations of the functions Kappa (κ(t)), rIT (ρIT), rSV (ρSV) and rRV (ρRV). We also see that the Kappa RAM has been selected. The Default option (number 0) of this RAM is the adaptive form given by Eq. 10 (it appears in the window on the left of panel A., with some specific details pertaining to this mode provided in the window on the right of panel A.). Inset B. shows the alternate form (number 1) for κ(t), which is simply setting it equal to the constant κ0. The user may insert an additional alternate form for this RAM by selecting the ‘plus’ button, bottom middle of panel B., and then adding the desired from in the Code window on the left-hand side
Scripting windows
Two types of scripting windows are available. The S On and JS On buttons (first and third buttons on top ribbon in Fig. 2) can be used to write or load in scripts respectively written in RPL (RAMP Programming Language; Fig. 5) or JavaScript. These scripts enable the user to control individual runs either by changing parameter values and RAM settings, or make multiple runs (Fig. 4) and plot these using the comparative window facility (Fig. 6). Accessing the window in which this script can be entered or loaded from a saved file is described in Fig. 4’s legend, as is accessing the window containing a list of the RPL commands that can be used to write such scripts.

Here we depict three panels or windows associated with the scripting utilities of our RAMPs. Panel A (black bordered panel): When the S On button (first button from the left on the top strip of a RAMP, as depicted in Fig. 2) is selected this window opens. In the bottom left corner of this window is a Command Reference button (covered here by panel C), when pressed, opens panel B. Panel B (blue bordered panel): RPL Reference window, containing a list of commands that can be used to automate multiple runs or make changes to component values or modes during runs. The second column of text in the Script window (panel A.) contains 17 lines of instructions (saved as MultiPrevScript.txt, as seen in the top right hand window slot of the S On window) that codes the RAMP to make six repeated runs of the model, where in each of the runs the value of KP0 (κ0) is increased in value from 0.5, starting with the value specified in the model and described further in Fig. 6. Panel C (orange bordered panel): When the JS On button (third button from the left on the top strip of the RAMP, as depicted in Fig. 2) is selected this window opens. Here we see the JavaScript equivalent of the RPL script given in panel A

The script depicted in Fig. 5 is used to run the deterministic SIRS+DTV RAMP 6 times using the parameters values depicted by the sliders (or fixed according to values listed in Table 1). The KP0 (top left-hand) slider in this figure shows a value of 4.5, which implies the 6 runs ranged from a start value of 2.0 to 4.5 in increments of 0.5. Note that each of the three graphs available on the dashboard has only one its several possible options selected (available options can be seen below the graphs in Fig. 2) and the small rectangular comparison window above each graph has been selected to ensure that graphs generated during each of the 6 runs remain plotted once all runs are complete. The c Clear button above each graph allows earlier graphs to be erased when desired
Help file and airport codes
When the Help menu of a RAMP is selected, information about the RAMP will appear together with a list of all the objects in the RAMP that can be referred to using airport codes (Fig. 7). In the parameter list on the left of Fig. 7), any parameter that has not been turned into a slider will have is Fixed Value listed in red. In our two SIRS RAMPs, though not in the our two SIRS+DTV RAMPs, the value of β (Airport code: BET) has been fixed 0.3 because only the product of κβ is relevant in determining the disease transmission rate ρSI for a particular prevalence level I(t)/N(t) (Eq. 7). The value of this product is thus manipulated using the κ0 slider, because κ0 scales the value of κ at time t, as expressed in Eq. 10.

When the Help menu of RAMPs is selected information about the RAMP is provided. Here we see the information provided about the stochastic SIRS+DTV RAMP. This information includes the airport codes for the parameters, variables, and graphs, as well as descriptions associated with the sliders, which can also be accessed by mousing over the relevant sliders on the Dashboard
Saving the data from each run
A file location can be set up for the automated saving of CSV files (see Fig. 8 for details), which is particularly useful when the RAMP is used to make a series of runs, each differing in some sense (e.g., but changing a slider value and then rerunning the RAMP). The user can select what values should be saved using the CSV Settings... window. As indicated in Fig. 8, each file is saved with its own date stamp. Each CSV file is automatically headed with the set of parameter values and RAMP selections that were used to generate the data in the file.

A. (black bordered panel) Each run can be saved at a user selected location that is set up using the pull down CSV menu on the top left-hand corner of the dashboard window (also see Fig. 2). B. (blue bordered panel) Once the CSV Settings option is selected a window opens that allows that user to select which disease states and computed time-series should be included in the CSV file which will be saved at the specified directory (example given here in the window at the bottom of the CSV Selection window. C. (orange bordered panel) Files saved in user specified directory are given a time and data stamp so that all files that are saved have a different name
Using RAMPs within the r statistical and data analysis platform
The exposition here applies to the use of Numerus Model Builder RAMPs as virtual packages in the implementation of R on the RStudio platform. The following steps should be followed to accomplish the match up between RStudio and NMB Studio (the Numerus Model Builder RAMP player) to implement the desired analyses.
-
1
Launch the RAMP to be used as an RStudio “virtual package” and either load the required parameter and RAM settings or choose these using the dashboard (Fig. 2).
-
2
Download the latest version of the nmbR package from the Numerus Studio site
-
3
Launch NMB Studio and install the package using the command
install.packages(~.../nmbR.tar.gz~, repos = NULL, type = ~source~) adding the appropriate directory.
-
4
Create the R code necessary to run the desired analysis, using the functions offered by the package, such as nmbR$iterate_r used in ex1 in Fig. 9
Fig. 9 
A partial capture of the RStudio window that is set up to run the iterate_r function of nmbR package. This package allows R code to utilize the RAMP currently running within NMB Studio as a ‘virtual’ R package
-
5
Here is a list of the different functions defined in the package, while the user can define any other desired function using R code. For more information about the package functions, use the command ?nmbR in the RStudio console.
-
nmbR$dispatch: to send a command string for processing by a running RAMP
-
nmbR$iterate_r: to iterate multiple runs, collecting in a list of per-run R data frames
-
nmbR$iterate_v: to iterate multiple runs, collecting in a list of per-variable R data frames
-
nmbR$frame: to retrieve the values generated in a RAMP simulation into an R data frame
-
nmbR$graph: to graph one or more time series from a RAMP simulation
-

Results: illustration of concepts
In this section, core epidemiological concepts and the efficacy of mitigating measures (treatment/isolation and vaccination) are illustrated through simulations, using parameter values and ranges of values listed in Table 3. These parameters are somewhat typical of a directly transmitted respiratory pathogen, such as COVID-19, but simplified by not including latent or asymptomatic disease classes [7,18], spatial structure [44], or age-class [22,45] and other population structure effects [9].
In the six subsections that follow here, we present illustrative examples that each culminate in a take home message—i.e., six in total. We also provide numbered simulation exercises in Appendix A (SOF), were each exercise is numbered to link it to the material presented in each of the 6 subsections of this section.
Deterministic SIR epidemiological dynamics
In our first simulation, we demonstrate the basic features of an SIR (and, equivalently, an SEIR) epidemic process. The actual set of parameter values is not important provided they are selected to ensure that R0>1. Beyond this, different sets of parameters will result in epidemics that have the same primary features of an outbreak curve: a rise, a peak prevalence, followed by a collapse to zero prevalence with a proportion of susceptibles escaping infection. The only difference is 1.) how long it takes the epidemic to rise to its peak and collapse to almost zero (in idealized deterministic models the approach to zero is asymptotic; in stochastic models it reaches 0 in a finite time—see “Stochastic SIRS dynamics” section for more details), 2.) the peak prevalence value itself, and 3.) the value of the proportion of individuals that escape infection.
For example, consider setting κ0=2 in the non-adaptive case (Eq. 9), β=0.3, ρIR=1/4=0.25, and ρID=0.05 (Table 3). In this case, it follows from Eq. 22 that \(R_{0}=\frac {0.3 \times 2}{0.25+0.01} = 2.353\). Since R0>1, we expect an outbreak to occur. As we see left most graph in Fig. 10, the curve Reff (blue curve) starts out at Reff(0)=R0=2.353. Despite R0 being almost 2 and half times larger than needed for an epidemic to occur, it takes time to make a visible impact in our plots, taking off around t=26 (see prevalence curve in red, in the left graph).

A view of the continuous-time deterministic SIRS RAMP dashboard after simulation of a basic set of epidemic SIR curves for the parameter values shown in the sliders, with an infectious period of 4 days, as listed in Table 1. Note the contact scaling value KappaS (aka behavioral switch, Pκ in Table 1) is moot because the Kappa Adaptive Contact RAM (green text in middle of panel) has been set to be Constant (roller setting is 1), while the setting for its Default mode would be 0 (also see Fig. 4). In this case peak prevalence is reached around 40 days, the herd immunity level is around 90% and the asymptotic susceptibility level S∞ is around 10%
As the prevalence rises steeply after this take off, Reff begins a concomitantly steep decline (blue curve, left graph), reaching a value of 1 around t=40. At this same time, the prevalence curve (red, left graph) hits is maximum value of just under 25% and then rapidly declines to low levels around t=60. Although deterministic models, as mentioned above, predict an asymptotic approach to 0 over infinite time, the last case will most likely disappear between 65-110 days (as discussed in “Stochastic SIRS dynamics” section), provided all of individuals in the R class (close to 90%, green curve right graph) remain fully immune (i.e., do not transition back to class S, as discussed in “Deterministic SIRS endemic dynamics” section).
Of notable importance is that not all individuals succumb to infection: at time t=100 days, the proportion of susceptibles is 0.124 (red curve, upper panel). The epidemic, though has run out of steam because most of the contacts between remaining infectious individuals I and others are with individuals from R who we have assumed cannot become reinfected, rather than from S. Further, at this time \(R\text {eff}(t)= R_{0} \times \frac {S(t)}{N(t)}\) is much less than 1. In fact Reff(70)≈0.3. It is important to note that the epidemic does not shut down when Reff(100)=1 around t=40 because it still has considerable momentum driving it down due to the prevalence at this point exceeding 20%.
Take Home Message 1.
An SIR epidemic after rising to a peak falls to approach zero prevalence as the herd immunity level is approach, while the proportion of susceptible individuals approaches a non-zero value. Thus, once the epidemic has passed not all individuals will have succumbed to the disease.
Deterministic SIRS endemic dynamics
In an SIR model, individuals remain permanently in R and thus remain immune for the rest of their lives. This corresponds reasonably well to the case of immunity to measles [46]. If we take the effects of waning immunity into account by allowing individuals to transfer back to S, then we obtain an SIRS model. The mean rate of return from R to S can be obtained from empirical observations on the rates of reinfection of previously infected individuals as a function of time since last infection. When this rate is positive, the epidemic is not extinguished but reaches some endemic state that depends on this rate. The level of prevalence that the population finally settles into is inversely related to the mean period of time it takes for individuals in R to return to S (Fig. 11A.).

The level of immunity (R(t)/N, left graph) and prevalence (I(t)/N, right graph) are plotted over 720 days for a set of comparative simulations of the deterministic continuous-time SIRS RAMP to illustrate the phenomena of endemicity as a function of waning immunity. Plots 1-6 represent loss-of-immunity rates of ρRS=0, 0.001, 0.002, 0.005, 0.01, and 0.03 respectively for individuals in class R. These corresponds to mean waiting (or residence) times in R (before returning to S) of ∞, 1000, 500, 200, 100, and 33.3 days respectively. Note that the value of the contact scaling rate KappaS =0.100 is moot because the Kappa adaptive contact RAM (Green roller below sliders) has been selected to be the constant value κ0=2 (see Fig. 4 for more details)
Take Home Message 2.
Levels of endemicity of a pathogen do not depend on R0, but on a given set of parameters that are inversely related to the waning period (i,e, mean residence time in R before returning to S).
Adaptive contact rates in the sIRS model
The trajectories depicted in Figs. 10 and 11 correspond to the case where the behavioral response is absent. An adaptive behavioral response can be implemented by setting the value Pκ in Eq. 10 to some finite positive value. For example Pκ=0.1 implies that the basic contact rate κ0 is reduced by half (i.e., to κ0/2) when prevalence is 10%. In Fig. 12B, we depict changes in the incidence curve for the basic set of parameter values in Table 3 for the SIRS model with mean recovery residence time is equal to 33.3 days rather than ∞ (note: the disease induced mortality rate in this case is 0).

The level of immunity (R(t)/N, left graph) and prevalence (I(t)/N, right graph) are plotted over 1450 days for a set of comparative simulations of the deterministic continuous-time SIRS RAMP to illustrate the effect of adaptive behavior as a function of disease prevalence. Plots 1-6 represent scaling parameter values of KappaS (i.e., Pκ in Eq. 10) respectively equal to 0.1, 0.033, 0.01, and 0.001 Note that the Kappa adaptive contact RAM roller is now blue because the default 0 option applies, as discussed in Fig. 4
Take Home Message 3.
Adaptive social distancing can do much to dampen the peak response in a rising epidemic, but does little to help extinguish the epidemic or set the ultimate endemic levels.
Stochastic SIRS dynamics
Stochastic SIRS models of epidemics in large populations (e.g. tens of thousands or more) behave very much like deterministic SIRS models, except at the start and end of an epidemic when infectious class sizes are small (single digits). The properties of stochastic SIR dynamics have reported in considerable detail in text books and review papers [42,47,48,49,50], but here we will only focus on the most salient differences between stochastic and deterministic SIRS models (Fig. 13).

A. A histogram of the duration of outbreaks of an SIRS stochastic process obtained from 1000 simulations of the stochastic SIRS RAMP depicted in Fig. 3 embedded in an RStudio computational environment. This histogram clearly indicates a set of minor outbreak (301 simulations) and major outbreaks (699 simulations), where the former constitute a set of stuttering transmission chains that are extirpated before they can engage their possible exponential grow phase [56]. B. A plot of the mean and spread (± 1 standard deviation) of the prevalence over the 699 runs that constitute the major outbreak component of the 1000 simulations
Arguably the most important insight obtained from a stochastic model is that even when R0>1, the introduction of an infectious individuals into a naïve population (i.e., with respect to the pathogen causing that disease or any related pathogens that may confer some cross-immunity in the population with respect to the pathogen causing the disease) does not automatically imply an outbreak of the associated disease will occur. In particular, it has been shown under certain assumptions, which we will refer to as the DH assumptions (see [1] for details of these assumptions), that the probability poutbreak is related to R0 by the equation
As an exercise, users of the Stochastic SIRS RAMP are asked to investigate how good an approximation Eq. 25 is for a SIRS epidemic modeled by Eq. 15.
A second important insight obtained from a stochastic model is that despite stochastic SIRS models predicting that all epidemics will ultimately become extinguished, endemic solutions persist for extended periods of time creating a so-called quasi-stationary distribution that depicts the distribution of prevalence values over time, given that the outbreak has past an initial epidemic burn in phase whose deterministic counterpart is the initial peak that we see in Fig. 11A before the equilibrium endemic level sets in [44,48,49].
Take Home Message 4.
The value (1−1/R0) provides an estimate of the probability that an epidemic will start when an infectious individual is introduced into a naïve population, although under the assumptions of our model it underestimates the probability of an outbreak by roughly 10% when R0 is in the 3-6 range (to verify this, see the solution to Exercise 4.1 presented in Appendix A (SOF) of the supplementary online material).
Treatment
From a modeling point of treatment introduces considerable complexity into the model that may require additional structure to comprehensively evaluate its effects. For example, only overtly symptomatic cases are likely to be treated, and type of treatment will depend on severity of infection. In addition, we may ask: 1.) Does the introduction of treatment reduce mortality of cases in I that are not treated, because these are the milder cases? 2.) Does treatment reduce transmissibility overall due to possible isolation during treatment of the severer cases in I? 3.) How does treatment impact that mortality rate of those removed to class T (treated class)? And, 4.) Should the population be structured into a class of healthcare workers that are involved caring for individuals in class T, because these workers are now at risk of infection from individuals in T while the general population is not (e.g., see [23]). All this suggests that the most appropriate way to extend SIRS models to include a T class will be disease specific.
In terms of general analyses that can be undertaken when introducing treatment in the very simple manner depicted in Fig. 1 and expressed mathematically in Eq. 20, we can look at: 1.) the effect that introducing T has on reducing transmission in a homogeneous population because of its isolating components, and 2.) reductions to mortality through both treatment and the possible introduction of novel treatments partway through the pandemic.
The first case can be explored, for example, by reducing the transmission rate of individuals in T compared with those in I. The second can be explored, for example, by assuming a relatively low disease-induced background mortality rate for all individuals left in I (perhaps even zero) and assuming that the disease-induced mortality rate of individuals in T is a decreasing (possibly step-wise) function of time as healthcare workers learn to deal with the new disease and pharmaceutical aids and methods of care improve steadily throughout the pandemic.
In Fig. 14 we compared two different scenarios that emphasize two aspects of treatment. To what extent is the capacity of the healthcare infrastructure going to be challenged by the peak number of individuals in treatment under the assumed treatment levels, and what are the expected number of individuals that will die from the disease over a specified period of time (in our cases 1000 days) under assumptions of how treatment will impact the mortality rate of those not in treatment, taking into account that those in treatment are the more severe cases anyway. The effect of scenario 2 compared with that of 1 is to reduce the peak number of individuals under treatment by around than 50% though due to different assumptions about the death rate under treatment leads to similar numbers of dead under both scenarios.

The per capita accumulating deaths (D(t)), the accumulating number of treatments (Ttotal(t)) and the prevalence (I(t)/N(t)), are plotted for two different constant treatment (i.e., ρIT RAM roller is set to 1) scenarios, with constant contact rate (κ0=2; Adaptive contact RAM set to 1) and no vaccination. In treatments 1 (blue curves) versus 2 (red curves) we have the treatment rates are ρIT=0.1 versus 0.02 (10% versus 2%). The parameters used in treatment scenario 2 are shown in the sliders here. In scenario 1, we assumed that the disease induced mortality rate is the same for individuals, whether they remain in I or move T, which implicitly assumes that treatment is taking the more severe cases and reducing the mortality of these case to same background rate of 0.5% for those untreated. In scenario 2, we assumed that treatment is more effective than in treatment 1, reducing the mortality rate of those under treatment to 0.1%
Take Home Message 5.
The incorporation of treatment into an SIRS models has several critical aspects to it that may require alteration of the SIRS+DTV model to assess the effects involved.
Vaccination
Vaccination rollout programs are limited by the willingness of the population to participate, the healthcare facilities available to vaccinate individuals at a particular rate, and the number of regimes that will be available over the rollout implementation period. A recent exposition by an ISPOR (International Society for Pharmacoeconomics and Outcomes Research) task force recommended that economic analyses undertaken to implement new vaccination programs should consider the following four components [51]: “ 1.) uptake rate in the target population; 2.) vaccination program’s impact on disease cases in the population over time using a dynamic transmission epidemiologic model; 3.) vaccination program implementation and operating costs; 4.) and the changes in costs and health outcomes of the target disease(s).”
The RAMPs that describe here are meant to help implement component 2. of the above recommendation. By way of illustration of this component—ignoring components 1, 3 and 4 which would need to be brought into a more complete analysis at some point— we compare two vaccination programs: one starting on day 100 and another at 250 days, where both are constrained by a program rollout rate of vaccination 0.3% of all not currently or previously infected individuals per day (i.e. ρSV=ρRV=0.003), with a maximum of one million regimens (irrespective of the number of shots associated with each regimen) available for the analysis.
The results of simulating the above two scenarios are illustrate in Fig. 15. The primary difference in the two scenarios is that the earlier start to the program helps suppress the second prevalence peak that occurs over days 200-300, and postponing it to a lesser peak over days 300-400. The early start does lead to a reduced proportion of deaths over days 200-700, but ultimately the advantages of the earlier start are nullified due to the earlier start program running out of vaccination regimens more than 100 days ahead of the later starting scenario.

The prevalence (I), number of individuals currently immune through vaccination (V), and the number that have died are plotted for the two contrasting cases. In Vaccination Scenario 1 (blue curves) versus 2 (red curves) we have vaccination rates ρSV=ρRV=0.003 (0.3% of individuals in these classes are vaccination each day) starting on day 100 for scenario 1 versus day 250 for scenario 2. Vaccinations are continued until one million regimens (whether done with a single or double shot is not relevant) have been delivered. Since the red curve initially obscures the blue curve, both scenarios are the same until day 100 (i.e., the initial red peak prevalence applies to both)
Take Home Message 6.
Vaccination policies with limited regimens available over some fixed planning period may need to consider trade offs between peak patient loads that may stretch healthcare resources and mortality rates over the periods in question.
Discussion
Some of the most challenging global issues of our time—climate change, habitat and diversity loss, emerging diseases, and food security—cannot be mitigated effectively without an adequate understanding of how dynamical systems unfold in space and time. Notions of how best to describe the systems involved and measure their variables and rates of change are central to uncovering the spatiotemporal characteristics of these systems. Concepts needed to understand these characteristics include: the impact of time constants on exponential growth; how interacting variables, adaptive behavior and time delays may induced oscillatory patterns; and, the probabilities of invasion, persistence, and extinction of salient species as a function of various rates and process descriptions. Uncovering these characteristics requires some level of mathematical sophistication (e.g., mastery of the fundamentals of calculus) and dynamical systems modeling.
In the context of emerging disease and associated epidemiological processes, public health policy decisions often need to be made by health policy professionals, politicians, and civil servants. Many of these individuals do not have the appropriate mathematical training and modeling experience to undertake the kinds of quantitative analyses needed to make the soundest health policy decisions. Given how consequential these decisions may be with regard to the health of individuals and the economic well being of society, it is important that tools be developed to assist those involved in formulating or implementing health policy to understand the basic concepts involved. This is where simulation modeling tools come to the fore as instructional aids in teaching these concepts to individuals who lack the mathematical skills to build and analyze epidemiological models themselves.
In an effort to identify software applications that are similar to or may compete with the applications provided along with this paper, we conducted a Google search using the search phrase “simulation tools for teaching epidemiological modeling.” This search, conducted on June 17, 2020, produced over 21 million hits. The first 50 hits included the following relevant links (in order of appearance): 1.) a link to the EpiModel site, which provides an R package for simulating and analyzing mathematical models of infectious disease dynamics; 2.) a link to the site Materials for Teaching the SIR and SEIR Epidemic Models (supported by the Mathematics Department at the University of Nebraska, Lincoln) that provides four downloadable modules: an SIR and an SEIR model implementation using either an Excel workbook template or a suite of R/Matlab programs; 3.) a link to FRED Web (Framework for Reconstructing Epidemiological Dynamics), which is a deeply formulated agent-based modeling system developed by the Pitt Public Health Dynamics Laboratory, and thus is not at all suitable as an introduction to SIR modeling; 4.) a link to Curb the Epidemic!, a hands on website designed to introduce 9th grade students to epidemic concepts and very simple agent-based simulation on a cellular array; 5.) a link to the QUBES Bioquest Project website Materials for Teaching the SIR Epidemic Model that provides a spreadsheet application for exploring the behavior of the standard SIR epidemic model; 6.) a link to the VENSIM site Coronavirus and Epidemic Modeling, which provides access to 6 vensim programs (in the form of name.mdl files) that need a version of the VENSIM software program to run. The remaining 44 hits referenced publications and talks, several referring to our own work and presentations, rather than sites providing implementable tools for simulating SEIR epidemics.
In short, in terms of tools to aid instruction in epidemiological dynamics, only a few groups have developed course notes and scripts to run SIR and moderately extended SIR models; and only then using either spreadsheets (e.g., [52]) R, MATLAB or other proprietary software platforms (e.g., Mathematics Department at the University of Nebraska, Lincoln). These tools are not stand alone applications programs of the type we present here, and require that students have a basic familiarity with the software coding platforms in question. Some educationally-oriented, web-based SIR modeling applications exist [53], as well as stand-alone applications programs [10], but their utility is limited by the relative simplicity of the models (e.g., they do not include treatment or vaccination options, and ignore the importance of adaptive contact behavior) and they do not have the flexibility of our RAMP technology to alter functional descriptions without needing to alter the underlying program codes.
Use of our RAMPs requires no coding or mathematical modeling skills, unless the user wants to write very simple scripts using our BPL or JAVA, or wants to use our RAMPs in conjunction with RStudio. It is important, though, that students are exposed to the primary assumptions underlying the construction of SIR models and their first line of extensions, as we provide in “Primary concepts” subsection. These assumptions provide insights into the limitation of the models and the actual complexity of the processes involved. The key to modeling is to capture the essential process involved and to understand the next level of processes that are being ignored by the models. This understanding facilitates assessment of the adequacy of the models as tools for making predictions and designing interventions [13,54,55].
Conclusion
The RAMPs and RAMP player (NMB Studio) described in this paper, downloadable at the Numerus Model Builder Website, provide a set of tools that mathematically unsophisticated students can use to come to grips with the most important dynamically systems concepts associated with the outbreak of communicable diseases of epidemic and even pandemic proportions. The installation of these RAMPs on laptop and desktop computers is as easy as clicking a button to locate the download site and install the application. All the information needed to run the RAMPs is provided with the RAMP itself in the form of information in windows, with more substantial details contained in this paper and its supplementary information files. In closing we stress that our RAMPs and associated documents are meant to augment existing course material rather than replace such material, because the history, etiological and other important information associated with specific diseases (COVID, influenza, ebola, measles, tuberculosis, HIV, etc.), classes and types of disease (respiratory, hemorrhagic, bacterial, fungal, etc.) and modes of transmission (airborne, waterborne, vectored, soilborne, bodily fluid exchange, etc.) are not covered in this paper.
Availability of data and materials
NMB Studio, which is needed to run the RAMPs, and the RAMPs themselves can be dowloaded at https://www.numerusinc.com/studio/.
Abbreviations
- COVID:
-
Corona viral disease
- DTV:
-
Dead, Treated, Vaccinated
- RAM:
-
Runtime alternative module
- RAMP:
-
Runtime alterable platform
- RPL:
-
Ramp programming language
- SIRS:
-
Susceptible, Infected, Recovered, Susceptible
References
Diekmann O, Heesterbeek JAP. Mathematical Epidemiology of Infectious Diseases: Model Building, Analysis and Interpretation vol. 5: Wiley; 2000.
Daley DJ, Gani J. Epidemic Modelling: an Introduction vol. 15: Cambridge University Press; 2001.
Vynnycky E, White R. An Introduction to Infectious Disease Modelling: OUP Oxford; 2010.
Keeling MJ, Rohani P. Modeling Infectious Diseases in Humans and Animals: Princeton University Press; 2011.
Li MY. An Introduction to Mathematical Modeling of Infectious Diseases vol. 2: Springer; 2018.
Gudbjartsson DF, Helgason A, Jonsson H, Magnusson OT, Melsted P, Norddahl GL, Saemundsdottir J, Sigurdsson A, Sulem P, Agustsdottir AB, et al.Spread of sars-cov-2 in the icelandic population. N Engl J Med. 2020.
Getz WM, Salter R, Luisa Vissat L, Horvitz N. A versatile web app for identifying the drivers of covid-19 epidemics. J Transl Med. 2021; 19(1):1–20.
Getz WM, Salter R, Luisa Vissat L, Koopman JS, Simon CP. A runtime alterable epidemic model with genetic drift, waning immunity and vaccinations. J R Soc Interface. 2021; 18(184):20210648.
Getz WM, Lloyd-Smith JO. Basic methods for modeling the invasion and spread of contagious diseases. DIMACS Ser Discret Math Theor Comput Sci. 2006; 71:87.
Getz WM, Salter R, Muellerklein O, Yoon HS, Tallam K. Modeling epidemics: A primer and numerus model builder implementation. Epidemics. 2018; 25:9–19.
Railsback SF, Grimm V. Agent-based and Individual-based Modeling: a Practical Introduction: Princeton University Press; 2019.
Getz WM. An introspection on the art of modeling in population ecology. BioScience. 1998; 48(7):540–52.
Getz WM, Marshall CR, Carlson CJ, Giuggioli L, Ryan SJ, Romañach SS, Boettiger C, Chamberlain SD, Larsen L, D’Odorico P, et al. Making ecological models adequate. Ecol Lett. 2018; 21(2):153–66.
Hethcote HW. The basic epidemiology models: models, expressions for r0, parameter estimation, and applications. In: Mathematical Understanding of Infectious Disease Dynamics. World Scientific: 2009. p. 1–61.
Jones JH. Notes on r0 vol. 323. Califonia: Department of Anthropological Sciences; 2007.
Blumberg S, Lloyd-Smith JO. Inference of r 0 and transmission heterogeneity from the size distribution of stuttering chains. PLoS Comput Biol. 2013; 9(5):1002993.
Park SW, Cornforth DM, Dushoff J, Weitz JS. The time scale of asymptomatic transmission affects estimates of epidemic potential in the covid-19 outbreak. Epidemics. 2020:100392.
Gao Z, Xu Y, Sun C, Wang X, Guo Y, Qiu S, Ma K. A systematic review of asymptomatic infections with covid-19. J Microbiol Immunol Infect. 2021; 54(1):12–16.
Ferretti L, Wymant C, Kendall M, Zhao L, Nurtay A, Abeler-Dörner L, Parker M, Bonsall D, Fraser C. Quantifying sars-cov-2 transmission suggests epidemic control with digital contact tracing. Science. 2020; 368(6491).
Yasaka TM, Lehrich BM, Sahyouni R. Peer-to-peer contact tracing: development of a privacy-preserving smartphone app. JMIR mHealth uHealth. 2020; 8(4):18936.
Schieffelin JS, Norton EB, Kolls JK, et al.What should define a sars-cov-2 “breakthrough” infection?J Clin Investig. 2021.
Glasser J, Feng Z, Moylan A, Del Valle S, Castillo-Chavez C. Mixing in age-structured population models of infectious diseases. Math Biosci. 2012; 235(1):1–7.
Lloyd-Smith JO, Galvani AP, Getz WM. Curtailing transmission of severe acute respiratory syndrome within a community and its hospital. Proc R Soc Lond B Biol Sci. 2003; 270(1528):1979–89.
Keeling MJ. The effects of local spatial structure on epidemiological invasions. Proc R Soc Lond B Biol Sci. 1999; 266(1421):859–67.
Lloyd AL, Jansen VA. Spatiotemporal dynamics of epidemics: synchrony in metapopulation models. Math Biosci. 2004; 188(1):1–16.
Watts DJ, Muhamad R, Medina DC, Dodds PS. Multiscale, resurgent epidemics in a hierarchical metapopulation model. Proc Natl Acad Sci. 2005; 102(32):11157–62.
Ajelli M, Gonçalves B, Balcan D, Colizza V, Hu H, Ramasco JJ, Merler S, Vespignani A. Comparing large-scale computational approaches to epidemic modeling: agent-based versus structured metapopulation models. BMC Infect Dis. 2010; 10(1):190.
Hastings A. Timescales, dynamics, and ecological understanding. Ecology. 2010; 91(12):3471–80.
Feng Z, Smith DL, McKenzie FE, Levin SA. Coupling ecology and evolution: malaria and the s-gene across time scales. Math Biosci. 2004; 189(1):1–19.
Dobson A. Population dynamics of pathogens with multiple host species. Am Nat. 2004; 164(S5):64–78.
McCormack RK, Allen LJ. Disease emergence in multi-host epidemic models. Math Med Biol. 2007; 24(1):17–34.
Gumel AB. Global dynamics of a two-strain avian influenza model. Int J Comput Math. 2009; 86(1):85–108.
Cai L, Li X. Analysis of a simple vector-host epidemic model with direct transmission. Discret Dyn Nat Soc. 2010; 2010.
Tien JH, Earn DJ. Multiple transmission pathways and disease dynamics in a waterborne pathogen model. Bull Math Biol. 2010; 72(6):1506–33.
Gilligan C. Mathematical modeling and analysis of soilborne pathogens. In: Epidemics of Plant Diseases. Springer: 1990. p. 96–142.
Getz WM, Gonzalez J-P, Salter R, Bangura J, Carlson C, Coomber M, Dougherty E, Kargbo D, Wolfe ND, Wauquier N. Tactics and strategies for managing ebola outbreaks and the salience of immunization. Comput Math Meth Med. 2015; 2015.
Kermack WO, McKendrick AG. A contribution to the mathematical theory of epidemics. Proc R Soc Lond A. 1927; 115(772):700–21. Containing papers of a mathematical and physical character.
Hethcote HW. The mathematics of infectious diseases. SIAM Rev. 2000; 42(4):599–653.
Getz WM, Pickering J. Epidemic models: thresholds and population regulation. Am Nat. 1983; 121(6):892–98.
McCallum H, Barlow N, Hone J. How should pathogen transmission be modelled?Trends Ecol Evol. 2001; 16(6):295–300.
Dougherty ER, Seidel DP, Carlson CJ, Spiegel O, Getz WM. Going through the motions: incorporating movement analyses into disease research. Ecol Lett. 2018; 21(4):588–604.
Allen LJ. A primer on stochastic epidemic models: Formulation, numerical simulation, and analysis. Infect Dis Model. 2017.
Akwa T, Maingi J. From ebola to covid-19: reshaping funerals and burial rites in Africa. J Health Commun. 2020; 5(3):7.
Riley S, Eames K, Isham V, Mollison D, Trapman P. Five challenges for spatial epidemic models. Epidemics. 2015; 10:68–71.
Castillo-Chavez C, Hethcote HW, Andreasen V, Levin SA, Liu WM. Epidemiological models with age structure, proportionate mixing, and cross-immunity. J Math Biol. 1989; 27(3):233–58.
Naniche D. Human immunology of measles virus infection. Measles. 2009:151–71.
Tuckwell HC, Williams RJ. Some properties of a simple stochastic epidemic model of sir type. Math Biosci. 2007; 208(1):76–97.
Allen LJ. An introduction to stochastic epidemic models. In: Mathematical Epidemiology. Springer: 2008. p. 81–130.
Britton T. Stochastic epidemic models: a survey. Math Biosci. 2010; 225(1):24–35.
Andersson H, Britton T. Stochastic Epidemic Models and Their Statistical Analysis vol. 151: Springer; 2012.
Mauskopf J, Standaert B, Connolly MP, Culyer AJ, Garrison LP, Hutubessy R, Jit M, Pitman R, Revill P, Severens JL. Economic analysis of vaccination programs: an ispor good practices for outcomes research task force report. Value Health. 2018; 21(10):1133–49.
Ledder G, Homp M. Materials for Teaching the SIR Epidemic Model. 2020. https://doi.org/10.25334/4H67-PT17. https://qubeshub.org/publications/1921/1.
Getz WM, Salter RM, Sippl-Swezey N. Using nova to construct agent-based models for epidemiological teaching and research. In: 2015 Winter Simulation Conference (WSC). IEEE: 2015. p. 3490–501.
Larsen LG, Eppinga MB, Passalacqua P, Getz WM, Rose KA, Liang M. Appropriate complexity landscape modeling. Earth Sci Rev. 2016; 160:111–30.
Getz WM, Salter R, Mgbara W. Adequacy of seir models when epidemics have spatial structure: Ebola in sierra leone. Phil Trans R Soc B. 2019; 374(1775):20180282.
Tritch W, Allen LJ. Duration of a minor epidemic. Infect Dis Model. 2018; 3:60–73.
Acknowledgements
None.
Funding
This research was funded by NSF Grant 2032264.
Author information
Authors and Affiliations
Contributions
WMG developed the models, generated the examples and figures, ran RAMP simulations, and wrote the manuscript with contributions and editing from the other authors. RS developed and coded all the software for the two applications programs: NMB Designer and NMB Studio. The former can run be used to build and run models, as well as generate Numerus Model Builder (NMB) runtime alterable model platforms (RAMPs) as HTML files that can then be read and implemented by the latter as a stand alone application. LV Was involved with the R implementation, ran R examples, checked all mathematical and RAMP coding components, and helped edit the final text. The author(s) read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
All authors have read the manuscript and agree to its publication in BMC Medical Education
Competing interests
WMG and RS, along with a third person, are owners of the LLC, Numerus Inc., which is responsible for releasing the applications program NMB Studio and the RAMPs required to run the models presented in this paper. Both the NMB Studio and the RAMP applications are available to download free of charge. Hence there are costs involved for anyone using these applications per the Numerus agreement with NSF who funded the development of this work.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
NMB Studio and the four NMB RAMPs described in this paper can be downloaded at NMB Studio by Numerus Inc.
Supplementary Information
Additional file 1:
Supplementary online file. This file contains the following Appendices: A. Simulation Exercises; B. Boxcar Models; C. Waiting Times in SIRS ABMs.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Getz, W.M., Salter, R. & Vissat, L.L. Simulation applications to support teaching and research in epidemiological dynamics. BMC Med Educ 22, 632 (2022). https://doi.org/10.1186/s12909-022-03674-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12909-022-03674-3